




第一作者:吴翔1,孙瑜尧2
通讯作者:高国一3,谢国彤2
作者单位:1上海交通大学医学院附属第一人民医院,2平安健康医疗科技有限公司,3首都医科大学附属北京天坛医院
Wu X, Sun Y, Xu X, Steyerberg EW, Helmrich IRAR, Lecky F, Guo J, Li X, Feng J, Mao Q, Xie G, Maas AIR, Gao G, Jiang J. Mortality Prediction in Severe Traumatic Brain Injury Using Traditional and Machine Learning Algorithms. J Neurotrauma. 2023 Apr 12. doi: 10.1089/neu.2022.0221. Epub ahead of print. PMID: 37062757.

文章摘要
颅脑创伤患者的预后预测对于临床决策与医疗政策的制定是至关重要的。本研究旨在建立模型预测重型颅脑创伤患者的出院死亡率,并应用内外部数据对预测模型进行验证。研究共纳入CENTER-TBI注册研究数据库54个变量,采用的预测模型包括逻辑回归(LR)、LASSO回归、以及两种机器学习模型:支持向量机(SVM)和XGBoost。研究通过C-Statistics评估各模型区分度,通过校准曲线的斜率及截距评估各模型校准度。训练集及内部验证集采用CENTER-TBI中国注册研究数据库的2804名重型颅脑创伤患者数据,外部验证集采用CENTER-TBI欧洲注册研究数据库的1113名重型颅脑创伤患者数据。研究结果显示XGBoost预后预测能力最优,显著优于传统逻辑回归及LASSO回归,且优于目前临床较常用的IMPACT及CRASH预后预测模型。通过递归式特征消除精简预测变量至26个后,XGBoost模型在外部验证中C-Statistic仍然可达0.87(95%CI:0.87-0.88)。但是继续精简预测变量后,机器学习模型较传统逻辑回归的领先优势逐渐缩小。本研究建立的所有模型均通过在线计算器的方式供临床医生应用。
研究背景
研究方法
一般临床预后预测模型的建立包括以下步骤:
1
数据收集
收集与预后相关的临床数据和特征。这些数据可以包括患者的基本信息、病史、体格检查结果、实验室检查结果、影像学结果等。
2
数据清洗和预处理
对收集到的数据进行清洗和预处理,包括处理缺失值、异常值和不一致的数据,进行数据标准化或归一化等。
3
特征选择和提取
根据相关领域知识和统计方法,选择最相关的特征并进行提取。这可以包括使用统计分析、特征重要性评估方法或机器学习算法进行特征选择。
4
模型选择和训练
根据预测任务的性质和数据特点,选择合适的预测模型,如逻辑回归、决策树、支持向量机、神经网络等。使用训练数据对模型进行训练和优化。
5
模型评估
使用测试数据对训练好的模型进行评估,评估指标可以包括准确率、召回率、F1分数、ROC曲线等。根据评估结果对模型进行调整和改进。
6
模型应用
将经过评估和优化的模型应用于新的患者数据,进行预测和预后评估。根据预测结果,可以为患者提供个性化的治疗方案和预后建议。
基于上述临床预后模型建立步骤,本研究设计与实施如下:
1
数据收集
研究纳入CENTER-TBI中国注册研究数据库的2804名重型颅脑创伤患者,以及CENTER-TBI欧洲注册研究数据库的1113名重型颅脑创伤患者。模型预测的预后指标为出院死亡率。研究共纳入54个预测变量,包括:患者的年龄、性别等人口学指标,伤因、类型等创伤相关指标,GCS、ISS等伤情严重程度指标,入院影像学表现,以及急症救治措施。
2
数据预处理
对数据库缺省值进行插补(均值插补或多重插补),对预测变量数据库进行数据格式整理,进行数据可视化观察是否有异常值,并进行校正。对连续变量进行标准化处理(Standardization),对分类变量进行独热编码(One-Hot Encoding)。
3
特征变量选择与模型训练
本研究除了应用全部54个变量进行模型建立外,为了简化模型,研究还根据递归式特征消除对预测变量进行精简并建立精简模型。本研究分别应用逻辑回归、LASSO回归两种传统统计学方法,以及支持向量机、XGBoost两种机器学习方法建立预后预测模型。研究对CENTER-TBI中国注册研究数据库的2804名重型颅脑创伤患者进行10折交叉验证(10-fold Cross Validation)。该过程将数据集随机分为10个子集,其中9个子集作为训练集分别训练4个模型,剩下的1个作为内部验证集,评估模型表现,依次循环10次,直至所有子集均经过验证。根据10次内部验证平均的表现调整各模型超参数。再次重复该过程直至达到最优超参数。为了避免随机化分组的影响,整个交叉验证过程重复10次。最后,根据最优超参数进行最终模型建立。

4
模型外部验证与评估
将CENTER-TBI欧洲注册研究数据库的1113名重型颅脑创伤患者数据作为外部验证集,对最终建立的逻辑回归、LASSO回归、支持向量机、XGBoost模型以及相应精简模型进行外部验证,主要验证参数包括C-Statistics评估各模型区分度,以及校准曲线的斜率及截距评估各模型校准度。模型评估采用DeLong检验进行各模型间C-Statistics的比较,并根据Bonferroni校正将α水平设为0.01。
5
模型应用
为了解决机器学习的“黑箱”问题,研究采用Shapley Additive Explanations(SHAP)对XGBoost模型决策过程进行进行解释及可视化。为了方便其他单位研究人员进行模型应用,包括XGBoost、SVM和LR在内的所有模型,均可以通过基于网页的计算器访问。
结果


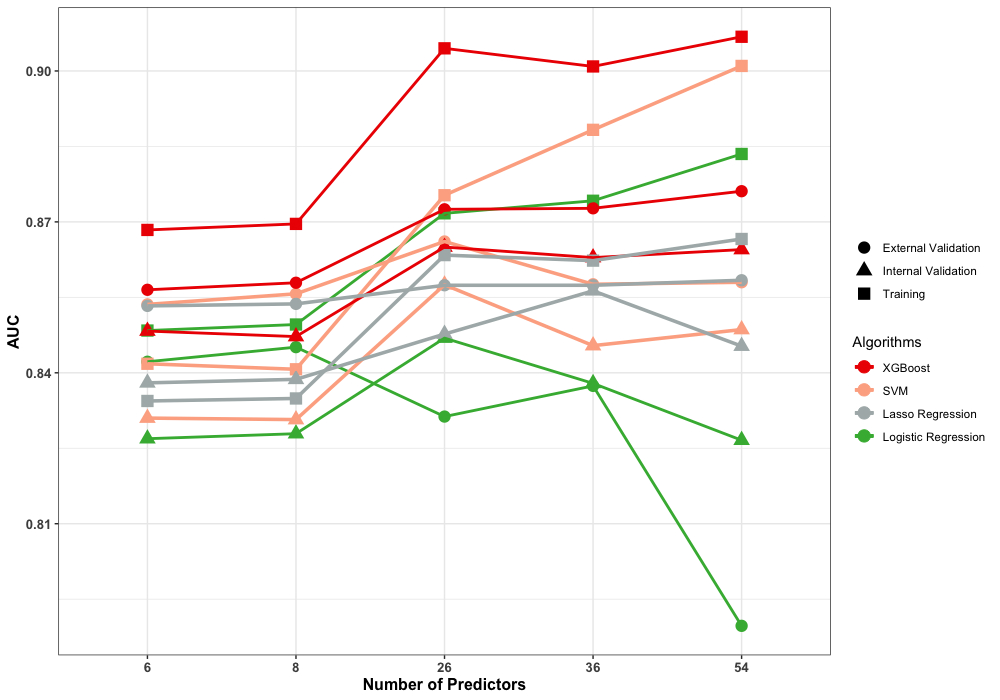
讨论
本研究建立了重型颅脑创伤患者出院死亡率的预测模型,模型纳入的变量主要为临床参数及评分,无需实验室指标,因此可在急诊室甚至更早转运中用于早期预测,以更高的进行临床决策制定、医疗资源分配以及医疗水平评价。相较于目前较为公认的预后预测模型,本研究建立的机器学习模型外部验证表现更优,其中原因可能与机器学习模型能发现某些变量与预后间的非线性关系(例如GCS、年龄以及ISS)。此外,本研究模型中某些预测变量,例如脑部ISS评分、二级转运等变量与预后关系在既往研究中也较少被发现。
此外,针对本领域前期研究存在的关于机器学习是否能提高预后模型预测表现的矛盾结论,本研究从预测变量数量方面进行探索。研究结果显示,传统统计学方法与机器学习随着预测变量增加时的表现是相反的。当纳入变量较少时,机器学习模型未展现出优势,但随着数量的增加,SVM、XGBoost模型优势逐渐显现,而传统方法稳健性较差。其中原因为,随着预测变量的增加,信号与噪音同时增加,而机器学习相较于传统建模方法可更好地排除噪音干扰、把握特征,从而实现更精准地预测。因此,逻辑回归等传统方法更适用于低维数据,而机器学习方法更适用于大数据量、多模态的数据集。目前,在神经重症领域,长时程、多模态的监测已得到越来越广泛的应用,再结合越来越多样的生物标志物以及影像学指标,机器学习可借助其优势,为提升TBI预后预测水平发挥重要作用。
结 论
本研究利用CENTER-TBI注册研究数据库建立重型颅脑创伤患者出院死亡的预后预测模型,并进行了内部及外部验证。研究结果显示,XGBoost模型在预测准确性及临床实用性方面都取得了较好的表现。此外,在神经重症领域大数据、多模态的背景下,机器学习在预后预测方面相较于传统统计学方法具有较大的优势。
第一作者简介

吴翔 住院医师
上海交通大学医学院附属第一人民医院
神经外科住院医师
上海交通大学神经外科博士,上海市优秀毕业生
以第一、共同第一或通讯作者在Lancet Neurology、Intensive Care Medicine、Journal of Neurotrauma等国际知名杂志发表论文多篇

孙瑜尧
平安健康医疗科技有限公司
硕士,平安科技资深算法研究员
在智能医疗技术研究领域从事算法研究多年,主要负责智能疾病预测方向的研究工作,曾在JNCI、CCM等顶级期刊上发表相关领域文章
通讯作者简介

高国一 教授
首都医科大学附属北京天坛医院
首都医科大学附属北京天坛医院创伤神经外科主任
神经外科教授,主任医师,博士研究生导师
中华创伤学会全国委员会委员
中华创伤学会神经损伤专业委员会副主任委员
中国神经外科医师协会颅脑伤专家委员会副主任委员
中华医学会神经外科学分会颅脑伤专业组副组长
世界神经外科联合会(WFNS)颅脑创伤委员会现任委员
Journal of Neurotrauma杂志亚太区编辑
承担多项国家级课题,在Lancet Neurology、Eclincalmedicine等杂志发表论著,获国家科技进步二等奖(排名第7)

谢国彤
平安健康医疗科技有限公司
博士,平安集团首席医疗科学家
负责平安集团的医疗人工智能技术研发
曾任IBM中国研究院认知医疗研究总监和IBM全球研究院医疗信息战略的联合领导人。在IBM研究院有近15年的从事人工智能领域研究的丰富经验,累计在国际会议及期刊上发表了50多篇论文,获得40项专利,3项IBM杰出研究奖,并于2016年被授予杰出IBM人
声明:脑医汇旗下神外资讯、神介资讯、神内资讯、脑医咨询、AiBrain 所发表内容之知识产权为脑医汇及主办方、原作者等相关权利人所有。
